
4月29日下午,迈普通信在“数字中国”现场,福州海峡会展中心9号馆新产品新技术发布区,隆重发布“信创AI智算交换机”,为保障AI算力网络供应链安全、加速AI基础设施国产化提供了新的选择。
现场汇聚行业专家、媒体代表及专业观众,共同见证迈普面向智算时代推出的AI智算交换机系列产品。
随着大数据与云计算技术向人工智能的快速演进,全球算力需求呈现爆发式增长,智算中心作为新型基础设施的核心载体,正向超大规模、超高算力方向加速演进。然而,算力激增对网络承载能力提出严峻挑战:如何实现超高速率、超高带宽、超低延迟、超高确定性的智算网络的构建?如何实现算力网络核心技术与供应自主、突破高端智算网络设备“卡脖子”困境?成为国内智算网络基础设施建设需要突破的关键。
迈普通信依托中国电子自主计算产业生态,结合多年信创技术沉淀,以澎湃的网络,为新一代智算中心构建坚实底座,实现卓越的算力。



本次迈普通信重磅推出「高性能AI智算多速率灵活插卡式交换机」、「新一代AI智算200G-400G盒式交换机」两个品类产品。主要面向企业级智算Scaleout参数面网络发布4款智算交换机产品。
高性能AI智算多速率灵活插卡式交换机
NSS5950-04C:4个业务槽,1G/10G/25G/40G/100G多种端口速率。主要适用于智算业务、存储、管理网核心融合组网。
NSS7830-09C:8个业务槽、1个主控槽、1个多业务扩展槽。整机支持128端口100G或64端口200G或32端口400G可变速率。主要应用于大规模100G、200G推理参数面Scaleout。
新一代AI智算200G-400G盒式交换机
NSS7810-24QV16QE:24端口200G+16端口400G,可灵活可变为40*200G形态。主要应用于200G训练/推理参数面Scaleout。
NSS7816-32QE:32端口400G,400G端口基于新一代4*112G Serdes。主要应用于400G训练/推理参数面Scaleout。
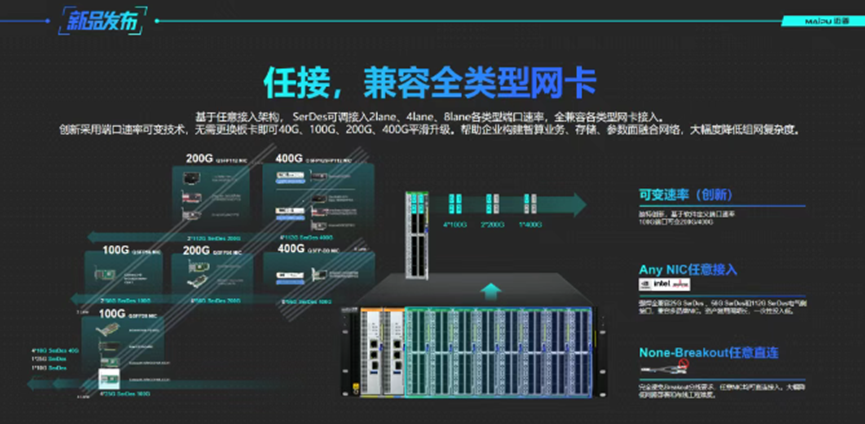

迈普通信深耕信创网络领域,以上AI交换机的发布,已形成数据中心“通算+智算”双场景全覆盖能力。立足国产核心技术,进一步挑战AI智算中心高带宽、低延迟、高确定性参数面网络的极致要求。主要特点包括:
中国“芯”,自主安全
基于国产关键元器件,从系统到网络协议栈全方位自主安全。
多主控,超冗余
创新首次实现国产盒式交换机多主控技术,双控制面冗余,增强可靠性。
灵活插卡,可变速率
基于任意接入架构,灵活插卡式型号业务板卡端口速率可调,无需更换板卡即可全兼容40G、100G、200G、400G网络平滑升级,保护用户投资。
智能无损(RoCE+AI)
基于无损以太加强(RoCE)技术,针对AI并行计算加强,通过大容量单交换芯片盒式架构,实现超低延迟、超高吞吐。交换时延可控制在≤1μs,网络吞吐量≥97.5%,关键报文实现0干扰,大包吞吐性能赶超国外同档次产品。
训推一体/存储面融合
轻松应对企业级100G、200G、400G训推一体规模组网要求。同时可实现智算全闪高性能存储NVMe over Fabric+INOF高吞吐、无阻塞要求。
面向下一代400G组网
400G端口支持QSFP112接口,支持新一代400G网卡直连,满足下一代200G/400G Q112级联组网,避免使用速率转换线缆,大幅降低组网门槛。
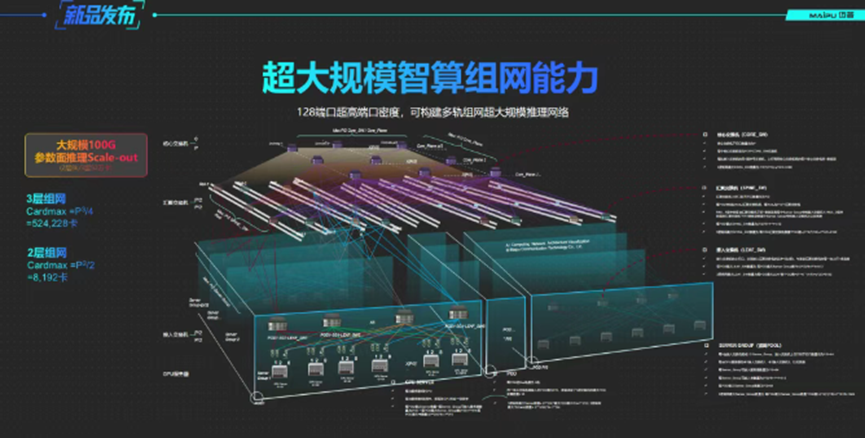
当前,基于本次迈普通信发布的信创AI智算交换机,企业级用户已经可以轻松应对智算在单轨和多轨模式下的规模组网要求。
NSS7830-09C,最大GPU/网卡接入能力可达:100G(2层组网 8192卡,3层组网524,228卡);200G(2层组网2,048卡,3层组网65,535卡)。可实现超大规模100G推理网络,中等规模200G训练/推理。
NSS7810-24QV16QE,最大GPU/网卡接入能力可达:200G(2层组网 800卡,3层组网16,000卡)。可实现中等规模200G训练/推理。
NSS7816-32QE,最大GPU/网卡接入能力可达:200G(2层组网 512卡,3层组网8192卡)。可实现中等规模400G训练/推理。

未来,迈普将持续以“建设中国人的安全网络”为使命,着力深耕智算网络相关技术,与各位行业伙伴一起,以“技术突破、生态开放”为战略支点,突破创新边界,推动智算网络与算力基础设施伙伴的深度融合,以网强算,建设AI时代安全网络!





